

No Safe Words
A single rogue token can erase production in 43 ms

Autonomous agents write code, move money, and make calls all without blinking an eye - yet 1 in 4 of their “confident” answers is fiction, and a single rogue token can nuke your production db in milliseconds. The companies winning in 2025 aren’t dialing back on autonomy; they’re doubling down on multi-layer guardrails, adaptive safeguards, and human risk checkpoints that slash policy breaches 20× and double task success.
The frontier work in safe agents proves there are no safe words —only safe systems.
AI agents are no longer sitting as shiny MVPs - in 2025 they are hitting production systems. Alongside the promised productivity utopia of an automated workforce comes an urgent question:
How safe are my autonomous agents in my production cloud?
We are fast forwarding into a world where we hand over control - are we equipped to let go without crashing and what are the pits lurking around the corner?
Reality Check
“BenchGPT wiped 8 months of bookkeeping in three weeks, bankrupting the firm.”
💡 Early adopters of a four-layer safety stack cut policy breaches 20 → 1 %, lift task success 77 → 86 %, and add < 1 s latency—cheap insurance for autonomy.
Failure Modes & Root Causes (”The Struggle”)
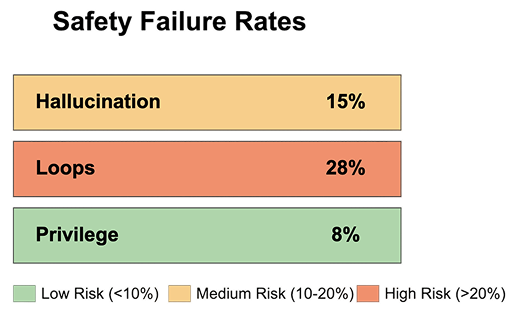
🤯 Despite < 2 % hallucination in lab LLMs, 70 % of live agent deployments still hit loops / goal-drift / privilege-spikes
How often do agents need a Human‑in‑the‑Loop?
Large‑scale benchmarks show ~27 % hallucination rate on open‑ended tasks.¹
Production logs in customer support and DevOps indicate manual escalation every few actions for higher‑risk workflows.
Best practice: position humans at risk checkpoints (e.g. financial transfers, destructive ops) rather than after every turn.
Reflection loops and memory retrieval reduce but do not eliminate these issues. Even a high per‑step accuracy does not guarantee long‑horizon success.
Mean Time Between Failure (MTBF): often a few dozen autonomous actions or minutes before drift.³
Mean Time To Recovery (MTTR): <1 step when safeguards auto‑trigger or a human intervenes; potentially hundreds of steps if unnoticed.³
we cannot engineer safety by anticipating every possible potential scenario - we have to model risk into our agents
Agent safety at a glance
Guardrails stop bad code from shipping; safeguards catch run-time disasters
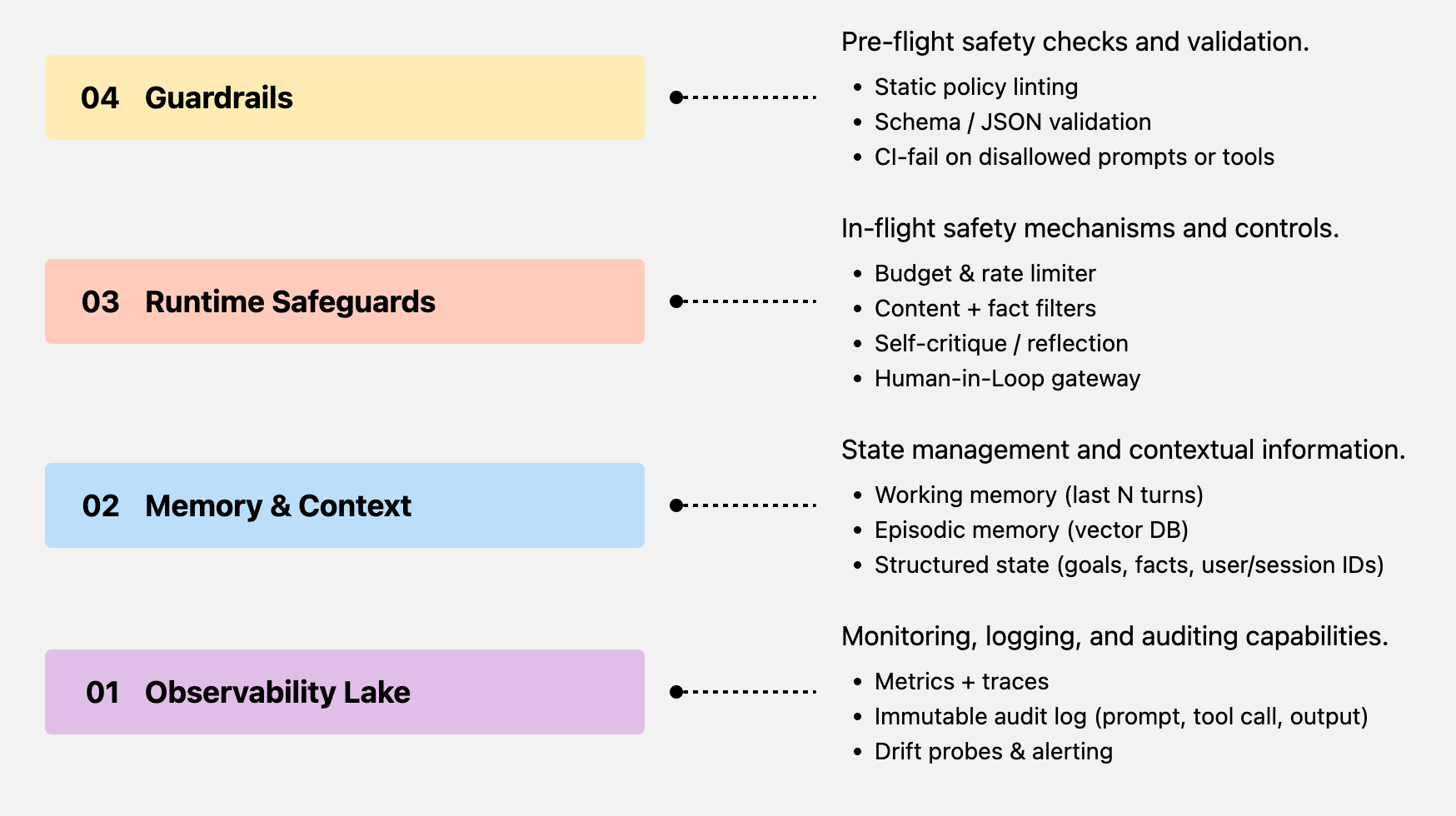
The 4-layer safety stack in a secure runtime provide the scaffold for agents to run safely in production clouds. Even as agents unlock access to tools and proprietary databases, the runtime ensures that every tool use, every knowledge sharing is justified and done with a safety first mindset. The runtime acts as the central sandbox, complemented with several key components :
Business Logic
Typed tool calls: expose tools as JSON functions so the LLM cannot free-form arbitrary code (OpenAI Function Calling)
Policy overlay: load domain rules (e.g., “refund ≤ ₹8 000 without HITL”) into the planner and reject plans that violate them.
Goal-diff guard: before executing the next step, do a diff(goal, proposed_action)—if drift > τ, trigger safeguard.
Human in the loop
Risk-scored routing: compute a risk score per action (value, blast radius, novelty). If score ≥ threshold, route to an approval queue (Slack/Email)
Timeout fallback: if no human responds in X min, agent fails-closed.
Align checkpoints with NIST’s “medium” and “high” risk outcomes (privacy, financial loss)
Safety & Risk Monitors
Rate & budget caps: per-agent and per-session token + $ budget.
Self-critique: run a cheaper “critic model” to veto hallucinations.
Systemic-risk model: compute an aggregate risk across concurrent agents (e.g., too many refund calls).
Guardrails
Content rails (toxicity, PII) + Structural rails (JSON schema, SQL whitelist) via
NeMo Guardrails (open-source; policy YAML + regex + callbacks)
Guardrails-AI (Pydantic-style validation)
Static “plan linter”: CI fails if an agent plan calls disallowed tool or passes raw creds.
NVIDIA showcased its layered AI safety stack in early 2024. In their factory example, a camera detected a worker entering a warning zone, which first triggered a visible alarm (proactive safety); if the person continued into a dangerous zone, the robot was automatically stopped (reactive safety) . combining multiple safety layers – from alerts to emergency shutdown – a multi-tiered safety stack in agentic systems is imperative not a nice to have.
Agent Safety Market & Architecture
Putting the 4 layers silicon wraps - for production we wrap the agent runtime with concentric safety rings:
Guardrails SDK (outer ring) – JSON / SQL schema validators, rate-limiter, privilege broker. Choices: Guardrails-AI, NVIDIA NeMo Guardrails, AWS Bedrock Guardrails, or hand-rolled pydantic types.
Risk Monitors (middle ring) – stream every tool-call to anomaly detector + budget counter, emit an audit tuple to a durable log (e.g., ClickHouse, Datadog, BigQuery). Vendors: WitnessAI, Arize Phoenix, Traceloop OpenLLMetry.
HITL & Recovery (inner ring) – risk-scored actions hit an approval queue (Slack/ServiceNow). A kill-switch micro-service can revoke the agent’s short-lived JWT in < 200 ms.

Best practices for production
Safe runtime contract
Agents receive only typed tools and least-privilege creds.
Every outgoing action returns {ok, risk_score, trace_id} so the monitor plane can gate, log or rollback. the WAF + SIEM for autonomous software.
Practical Deployment patterns
Side-car (k8s) – inject guardrail proxy as a container next to the agent; zero code-changes.
Reverse-proxy – front agents with Envoy/Nginx that calls the guardrail policy plug-in.
Function-as-a-Service – run each agent call in an serverless function (CF workers, AWS Lambda) wrapper for natural rate-limiting and IAM scoping.
Target for the below metrics with your Observability stack
Latency SLO: < 250 ms p95 per guardrail hop.
MTBF target: 1 h autonomous runtime before drift.
MTTR target: ≤ 1 step after safeguard trip or HITL reject.
Running in Production
Vector Store Risk Mitigation Embeds raw PII Hash/perturb before embed Prompt echoes user secrets PII redaction + refuse mode Retrieval leaks proprietary code Tenant‑scoped indices
Minimal audit tuple: {timestamp, agent_id, prompt, tool_call, output, decision_trace}.
Visualizing a reasoning tree or Sankey of tool invocations speeds RCA (root‑cause analysis) by 2×, per incident‑response studies.

Least‑Privilege Tokens
Autonomous agents often act on behalf of users or services. Over‑broad credentials exaggerate blast‑radius.
Key design points
Time‑boxed tokens (task execution time) curb lateral movement.
Scope‑boxed permissions (per‑task) follow least privilege.
Auditable claims: every agent action carries a trace‑ID & signer
Mis‑step Consequence Safeguard Long‑lived admin token Global compromise Auth proxy issues short‑lived creds Scope: *:* Deletes prod DB Policy engine rejects non‑scoped token
Cloudflare released a new AI audit tool in Sept 2024 to increase observability. Site owners can now see exactly which AI models (and what content) have been crawling their pages . It detailed analytics by AI provider and even a one-click option to block unwanted AI crawlers. This example illustrates governance in practice: detailed logging and controls give stakeholders clear visibility into agentic actions on their data.
Need the step-by-step recipe? See the Credential Safety Playbook for Rotate → Audit → Revoke
Practical Agents
✨ Pass every checkbox, then ship. Agents will never be “fully-safe”, but this checklist pushes them into the statistically safer, faster-recovery zone documented throughout the article.
Define Scope & Blast-Radius
Pre-Deploy Guardrails
Simulation & Stress-Tests
Staging / Shadow Mode
Launch Go/No-Go Gates
Production Safeguards
Observability & Incident Response
Continuous Evaluation
Documentation & Training
Get access to the full Practical Agents Checklist
In July 2024, NIST published the “Generative AI Profile” of its AI Risk Management Framework . This guide helps organizations identify risks unique to generative AI and proposes actions to manage them. The NIST profile acts as a safety checklist of best practices (security, testing, documentation) for deploying real world AI agents.
Cost ↔Benefit
Policy attacks dropped from 20 % → ≈ 1 % after multi‑layer safeguards.⁵
Benchmark task success jumped 77 % → 86 % with reflection self‑repair.⁶
Hallucination rate nearly halved when agents used retrieval + verification.¹
Cost overruns prevented by loop breakers & budget caps (qualitative industry data).²
🧚🏼 Economics is front & center for enterprise use-cases.
IBM’s October 2024 analysis found AI compute costs soaring (projected +89% by 2025) and reported that 100% of surveyed executives had canceled or postponed at least one AI project due to expense . Seventy percent cited generative AI as the culprit.
an agent’s promised gains must outweigh its high resource demands. If operating an AI agent is too costly relative to its benefits, organizations will pull back, effectively acting as a safety check via economics.
Frontier best-practices to lean in on
Self‑Critique & Reflection: agents learn from their own mistakes in‑flight
Adaptive Safeguards : rules tighten dynamically based on live risk signals.
Long‑Context & Typed Tooling: 1mn‑token windows to reduce temporal hallucination + strict JSON/DSL schemas
3 Bold Predictions + 2025 Watchlist

Github Repo
https://github.com/cirbuk/plan-lint
References
Research
Why Do Multi-Agent LLM Systems Fail? – taxonomy of 14 failure modes (2025).
Safeguarding AI Agents: Pre-/In-/Post-Planning Layers (2024).
BrowserART: Refusal-Trained LLMs Are Easily Jail-broken as Browser Agents (2024).
Can We Rely on LLM Agents to Draft Long-Horizon Plans? (2024).
An Empirical Study on Factuality Hallucination in LLMs (2024).
Reflexion: Self-Reflection Improves Decision-Making Agents (2023).
AutoHallusion: Stress-Testing Hallucination under Context Traps (2024).
Industry White-Papers & Tech Reports
Microsoft Security Blog – AI Watchdog: Mitigating Evolving LLM Attacks (Apr 2024).
NVIDIA – NeMo Guardrails Security Guidelines (Jan 2025).
Dynatrace – Reducing Incident MTTR with AI Ops Templates (Mar 2025).
Scale AI – BrowserART Launch & Findings (Feb 2025).
Reuters Legal – AI Agents: Capabilities & Risks (Apr 2025).
Benchmarks & Toolkits
BrowserART Benchmark GitHub (2025).
MobileSafetyBench Leaderboard (2024).
AgentSafety Papers List (2024).
Social Posts (last 6 months)
@OpenledgerHQ – “An AVS layer can act as a secondary check …” (16 Apr 2025).
@scale_AI – “BrowserART benchmark highlights gap in agent safety” (30 Mar 2025).
LinkedIn – Sahin Ahmed – “Guardrails in AI aren’t optional — they’re infrastructure.” (3 Apr 2025).